Transformers and the Attention Revolution
My wife and I recently just had our first child! So as hectic and "transform"-ative as it's been I've also had some time to reflect and dive a bit deeper into topics I find interesting. One of those being the "self-attention" mechanism and transformers which leverage it, so I wanted to share some of the interesting experimentation that I've done. To me the most fascinating aspect of transformers is their generality. So far we've seen transformers largely popularized in the field of NLP with models like BERT and GPT. However, transformers and self-attention mechanism are not limited to NLP and can be applied to a wide variety of problem domains. Part of my movitation to experiment has been to explore the use of transformers in the context of continuous time series data and I'll share some of those results here.
So first off I want to give a shoutout to Peter Bloem for his excellent blog post on the topic of transformers and self attention. I've read the original Attention is All You Need paper by Vaswani et al. but have always found it a bit dense. I think the paper, as seminal as it is, focuses a lot on very specific implementation of a transformer (encoder/decoder transformer architecture) and as a result has a lack of emphasis on the important implications of transformers as general all purpose model architectures. Peter's blog post does a great job of breaking down the key concepts behind these models and I highly recommend it. You can find it here. I also used some of the code from his blog post to help me get started with my own experimentation.
The first thing I wanted to do was to implement a simple transformer model to see how it would perform on the IMDB sentiment analysis dataset and more or less recreate the results from his blog. I did make a few changes to the transformer implementation. When all was said and done, the model was able to achieve an accuracy of 86% on the test set which I was quite impressed with. Here's some of the key changes and hyperparameter selections I made:
- Rewrote the code to pull in the IMDB sentiment analysis dataset (the python module which was used to pull in the data seems to be deprecated)
- Developed my own tokenizer that was easier for me to understand
- Introduced a sinusoidal positional encoding mechanism, since this is the type of positional encoding I'm most familiar with. I also experimented with entirely learned positional encodings, but that didn't seem to achieve the same level of performance.
- Deepened the network to incorporate 10 transformer blocks
- Added dropout of 0.2 to prevent overfitting (although overfitting is still observed since the negative log likelihood training loss converges to 0, while validation accuracy plateaus at 0.86). I experimented with different dropout rates but 0.2 seemed to work best.
- Used a larger batch size to improve training speed (I used a 4070Ti GPU on my personal computer to do this)
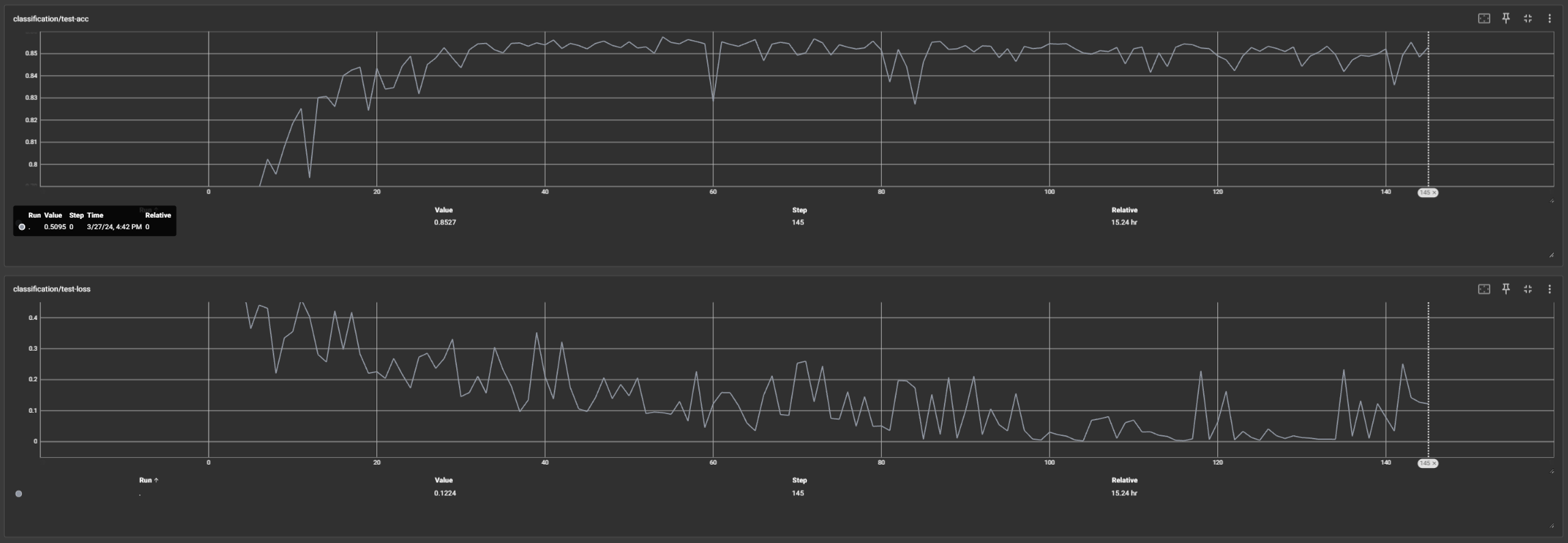
Overall I was very impressed with how quickly and accurately the model was able to perform given the limited data available and model simplicity. I was also impressed with how quickly the model was able to train. One thought I had was that it would've been nice if the data was labeled with the overall rating of the movie (1-10) instead of just positive or negative sentiment. I think this would've allowed the model to learn a more nuanced semantic representation of the data and potentially improve performance. The validation accuracy/loss curves can be seen below.
I also thought it would be interesting to capture the attention weights of the model and visualize them. I was able to do this by generating heatmaps for the attention weights in the final layer of the transformer. You can see the heatmaps for each of the final attention heads below. It's hard to say exactly what the model is learning from these heatmaps, but it's clear that the model is able to learn some sort of semantic structure.
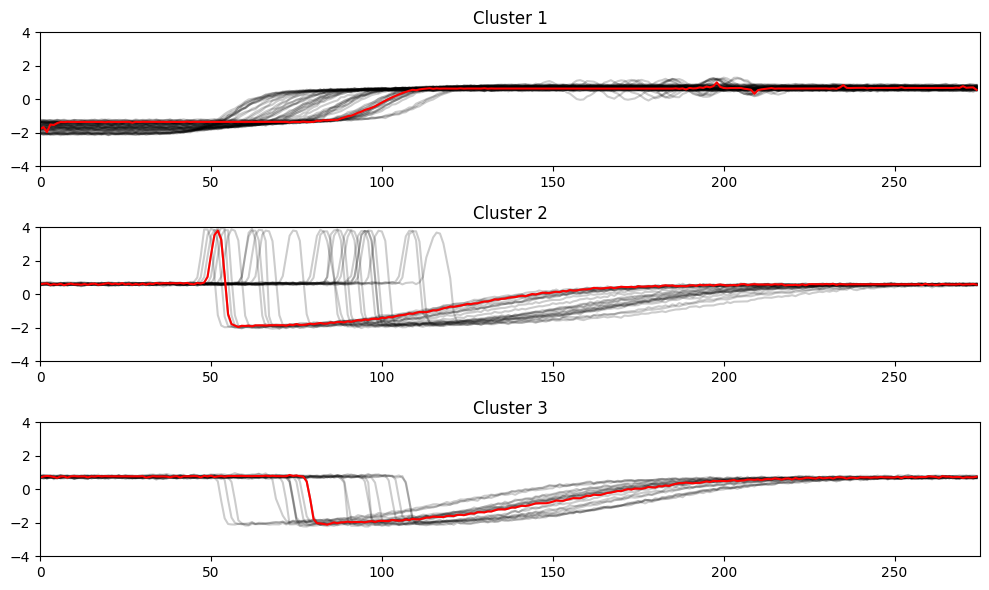
Next, I wanted to apply this model to a continuous time series dataset. I decided to use the "Trace" dataset, which is a dataset of continuous time series data that is used to benchmark time series forecasting models. You can see a visualization of the 3 different Trace classes below:
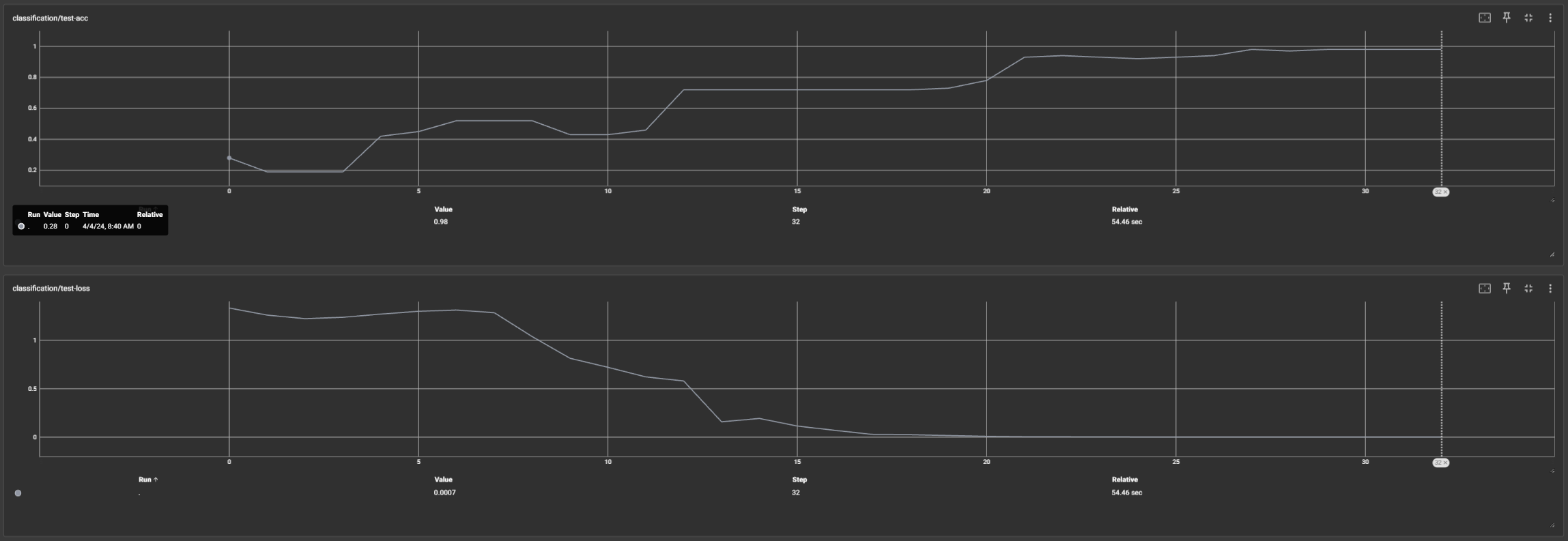
I used the same transformer architecture as before, but made a few key changes to the model. This time I projected the input time series to an embedding space before feeding it into the positional encoding and transformer blocks. I also experimented with different positional encoding mechanisms and found that learned positional encodings worked best. Sure enough the model was able to achieve 100% accuracy within just a few epochs. One thing I find particularly interesting is that the model was able to easily and accurately learn the dataset despite the fact that each sample is "shifted in time". This is a common challenge when dealing with time series data, and often time techniques like dynamic time warping are used to deal with it, but the transformer architecture clearly had no issues learning beyond this property. Overall I'm not surprised by these results given how simple the dataset is, however, I think it's good evidence to show that transformers can be applied to continuous time series data and achieve good results.
I think the application of transformers to new data domains is an extremely promising direction for future research and I think as data and compute become more available, we will see transformers become more and more popular in other domains. Shortly after doing this experimentation, I came across this site which describes some leaked components of GPT-4, which as of now is OpenAI's latest and greatest language model. The model is absolutely massive with 1.75 trillion parameters. As promising as transformers are, I think it's important to remember that impressive performance we see with state of the art language models is also in large part due to the massive amount of data and compute that is available to train these models with. Unfortunately it's very difficult to achieve performance parity without access to those same resources. The same also applies to other domains... labeled data and compute is always expensive and hard to come by and will always be a limiting factor in the development of models that truly push the envelope of performance. So before we see people start to exploit the powerful capabilities of transformers in other domains, we will need to see large amounts of capital investment in the form of data collection and compute - which is not a trivial task. That being said, I think the future is very bright for transformers and I'm excited to see where the field goes from here.
You can find all my code at my github here .